Post:
Development Approach
Insights
What
Why
- Resumir (summarize) los registros en el SiB de acuerdo a su nivel taxonómico, tipo de registro y organización publicadora (distribution).
- Buscar (browse) el número de registros para un cierto nivel taxonómico, tipo de registro y/o organización (distribution).
- Descubrir (discover) la contribución de cada organización en cuanto a tipo de registro y cada nivel taxonómico (features).
How
Marcas
- Tipo de Registro: Áreas para representar cantidades.
- Todos los niveles taxonómicos: Líneas para representar cantidades.
Canales
- Tipo de Registro: Región espacial y color para cada valor del atributo.
- Todos los niveles taxonómicos: Región espacial para cada valor del atributo y la posición en una escala común para las cantidades.
- La escala de la visualización de Reino es raíz cuadrada, mientras que para las otras es escala lineal.
Contexto
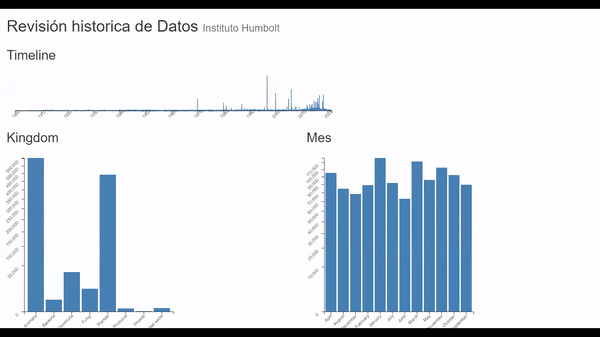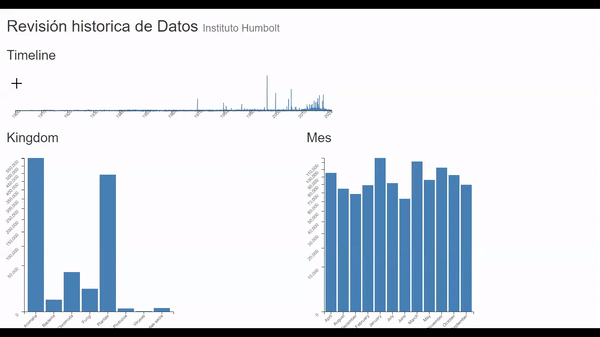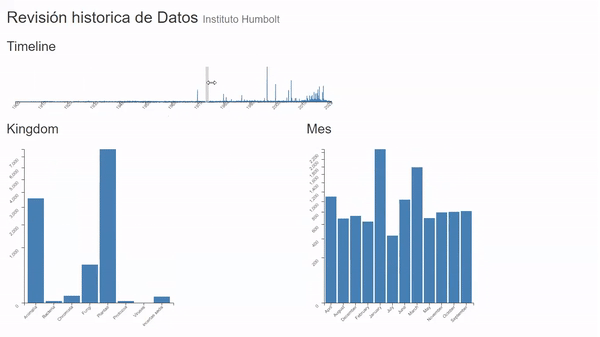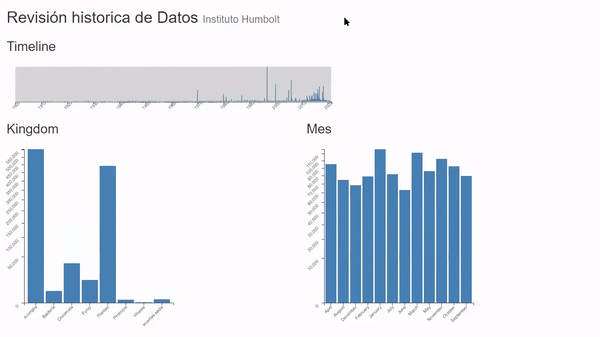
La tarea consiste en tomar un universo de datos mayor a 7 millones de registros y poder ubicrlos en el tiempo vs su tamaño para así poder entender en que meses se produce por ejemplo el mayor ingreso de registros o viceversa y a su vez poder tener una revisión general del kingdom y el mes al que pertenecen según la fecha en el que se produjo el registro.
What
Why
- Comparar (compare) la cantidad de registros a lo largo del tiempo y su participación a nivel mensual. (Trends).
- Identificar (Identify) mínimos y máximos, que meses son en los que más se realizan publicaciones. (Outliers).
- Buscar (Browse) Los años y meses donde más hubo participación de algún kingdom en específico. (features).
How
Marcas
- Cantidad Registros vs Tiempo: Líneas para representar Cantidades
- Cantidad Registros vs Mes: Líneas para representar cantidades.
- Cantidad Registros vs Kingdom: Líneas para representar cantidades.
Canales
- Cantidad Registros vs Tiempo: YAxis: Cantidad Registros, XAxis: Timestamp.
- Cantidad Registros vs Kingdom: YAxis: Cantidad Registros, XAxis: Kingdom.
- Cantidad Registros vs Mes: YAxis: Cantidad Registros, XAxis: Mes.
- La escala de la visualización de cantidad de registros en el TimeLine es líneal mientras los diagramas de barras son raíz cuadrada.
Encode
- Cantidad Registros vs Tiempo: LineChart.
- Cantidad Registros vs Mes: BarChart.
- Cantidad Registros vs Kingdom: BarChart.
Insigths:
• Entre 2010 y 2011 se produjo en mayor número de registros de especie no identificada o incertae sedis, lo que podría como una errada clasificación de la información o el hallazgo de una clasificación nueva
• La mayor concentración de registros de tipo Bacteria se encuentran entre los años 2011 y 2015.
• Los virus es la categoría de menor cantidad de registros adicional que su mayor concentración se encuentra entre los años 2012 y 2014.
• El mes donde menor inserción de datos hay es Junio
• Aunque el Kingdom tipo Animalia es el más alto en general, no siempre fue así, pues Plantae siempre tuvo su liderado hasta el año de 1900 y recuperando en 1920 hasta 2016
Caracterización del problema:
El SiB Colombia es la red nacional de datos abiertos sobre biodiversidad. Esta iniciativa de país nace con el Decreto 1603 de 1994 como parte del proceso de creación del Sistema Nacional Ambiental (Sina), establecido en la Ley 99 de 1993, y es el nodo oficial del país en la Infraestructura Mundial de Información en Biodiversidad (GBIF). Su principal propósito es brindar acceso abierto a información sobre la diversidad biológica del país para la construcción de una sociedad sostenible. Además, facilita la publicación en línea de datos e información sobre biodiversidad, y promueve su uso por parte de una amplia variedad de audiencias, apoyando de forma oportuna y eficiente la gestión integral de la biodiversidad.
El SiB Colombia es una realidad gracias a la participación de cientos de organizaciones y personas que comparten datos e información bajo los principios de libre acceso, transparencia, cooperación, reconocimiento y responsabilidad compartida.
Más y mejor información disponible, conectada y consolidada, que se transforma en conocimiento para conservar, aprovechar y conectarse con la biodiversidad. (tomado de: https://sibcolombia.net/el-sib-colombia/)
Una de las mayores necesidades de El SIB Colombia en este momento es poder mostrar a los socios la valía de la organización en cuanto a manejo de recolección y administración de datos de biodiversidad, como los usuarios publican registros de la biodiversidad colombiana, como estos están clasificados por tipologías, regiones y tiempo. A partir de esta necesidad se plantea la construcción de visualizaciones que permitan mostrar las publicaciones realizadas por la comunidad su uso y administración a lo largo del tiempo, también se espera poder obtener Insigths relevantes que sirvan para la toma de decisiones encaminadas en generar estrategias que agreguen valor al SIB Colombia.
Descripción del proceso realizado:
Para poder construir las visualizaciones se toma como insumo los registros históricos de El SIB Colombia, este archivo este compuesto por 7’386.568 de registros, cada uno representa una publicación.
Cada registro esta compuesto por las siguientes variables (La descripción de estas se puede encontrar en la pagina oficial de el SIB Colombia https://sibcolombia.net/)
Variables: occurrenceID, basisOfRecord, collectionCode, kingdom, phylum, class, order, family, genus, taxonRank, scientificName, eventDate, day, month, year, stateProvince, countryCode, county, locality,d ecimalLatitude,d ecimalLongitude,e levation.
Manipulación Datos: Teniendo en cuenta que las visualizaciones se presentan sobre un navegador con recursos limitados es importante poder resumir, comprimir… de alguna manera la información y de esta forma poder presentar un archivo mas liviano que pueda ser consumido desde un navegador sin generar demoras, para esto se realizan una seria de pasos descritos líneas abajo.
Proceso ETL: para la depuración de los datos y la transformación se realizan 3 pasos fundamentales, cada uno de estos pasos esta representado a nivel técnico por una aplicación java 1.8.
• Extracción: Partiendo que el archivo tiene mas variables de las necesarias para la tarea, se decide hacer una extracción inicial donde se obtienen las columnas necesarias para la construcción de las visualizaciones.
• Transformación: El siguiente paso fue realizar una validación de datos donde se encontró una serie de inconsistencias en cuanto a nombre Pj. Se encontraron varios nombres para Antioquia: (antioquia, ANTIOQUIA, Dep. Antioquia), con el fin de unificar estos datos se hace una validación y estandarización de nombres, esto para departamentos y municipios.
• Carga: Por ultimo la información generada debe ser comprimida esto se hace por medio de la agrupación de valores comunes Por elemplo: se encontraron 20 registros de publicaciones en el municipio del santuario Antioquia, estos registros se suman y se hace un consolidado (Departamento: Antioquia – Municipio: El Santuario – Numero de publicaciones: 20). Finalmente, el cvs es transformado en un .json y cargado en GitHub.
A continuación, la ruta GitHub de la aplicación (ETLComponent.jar): https://github.com/juanfer960/ETLComponent.git
Presentación de las visualizaciones: Para la presentación de la visualización se usa D3.js sobre una pagina web (Boostrap, HTML, css).
Grafica del proceso de ETL para los datos:
.png)
Análisis (What?,Why?,How?):
Análisis: (Este análisis corresponde a la tarea 3)
What?:
Descripción del Data Set:
Es un archivo SVC separado por comas, con 22 columnas y 7’386.568 filas. Cada fila representa una publicación realizada sobre biodiversidad de la Fauna colombiana en un lugar y época definida.
Atribut types: (A continuación, se describen los atributos utilizados en la tarea 3)
• Departamento: Categorical
• Municipio: Categorical
• Numero de Publicaciones: Order cuantitative
Why?:
(Summarize - Features)
Tarea 1: (Principal): Resumir las ocurrencias(registros) de acuerdo con el área o ubicación donde se genero esta.
((Identify - Extremes))
Tarea 2: (Secundaria): Identificar zonas con mayor y/o menor número de ocurrencias(registros) dentro de Colombia y/o del departamento seleccionado.
(Lookup Features)
Tarea 3: (Secundaria): Buscar el numero de ocurrencias (registros) en un zona en particular, dentro del territorio colombiano, ya sea a nivel departamental o municipal con características particulares.
(Compare Features)
Tarea 4: (Secundaria): Comparar el numero de ocurrencias(registros) entre departamentos y entre municipios.
How?:
Visualización uno: (Zoomable Circle Packing)
• Marks: Points
• Chanels: Size (area)
Encode: Separate
Modismo: Zoomable Circle Packing
Iteración: Navegar dentro de los departamentos para observar con mas claridad los municipios (Zoomable Circle)
Visualización dos: (Hierarchical Bar Chart):
• Marks: lines
• Chanels: Vertical position, horizontal position
Encode: Expres, Order, Align
Modismo: Hierarchical Bar Chart
Iteración: Posicionarse sobre una de las barras de departamento y poder desplegar un bar char con los municipios.
Visualización tres: (DashBoard: interaction between Bar Char and pie chart):
• Marks: lines
• Vertical position, horizontal position, Zise – area (para el pie chart)
Encode: Expres, Order, Align
Modismo: Hierarchical Bar Chart – Pie Chart
Iteración: Al posicionarse sobre alguna de las barras de los departamentos se pude validar el numero mas alto de ocurrencias(registros) por municipio para este departamento, la media de ocurrencias(registros) para ese departamento y el menor numero de ocurrencias en un municipio para ese departamento.
Insigths:
• Para la mayoría de los departamentos hay un municipio que genera el mayor numero de ocurrencias (registros, publicaciones).
• A pesar de que zonas como San Andrés y Providencia y Amazonas son ricas en fauna no son de los departamentos que aportan mayor numero ocurrencias (registros, publicaciones).
• En todos los departamentos hay aportes que no tienen definido municipio y por lo general son un numero grande los que tienen esta característica, generando algo de oscuridad sobre los resultados. (Por lo menos para generar las cantidades de ocurrencias publicadas por municipio)
• El departamento que mas ocurrencias aporta es Antioquia con mas de 800.000 ocurrencias, seguido por el Valle del Cauca y Caldas
• Para la mayoría de los departamentos el municipio o región con mas aportes son grandes zonas hurdanas factor que es entendible por el numero de personas que habitan estas urbes, pero un poco contradictorio ya que este tipo de trabajo debería estar centrado en zonas con alta diversidad biológica como lo puede ser las zonas costeras o el amazonas.
• El departamento con mayor numero de aportes con municipio indeterminado es Valle del Cauca con 537999 seguido de Antioquia con 456915.
• El aporte promedio entre los 10 principales municipios es de 8.974 registros por municipio.
• El departamento con menos aportes es San Andrés y Providencia con menos de 200 registros